AIBaseAI Computing Infrastructure
Large model fine-tuning and small model full training run in parallel, from data preparation, training, evaluation to release and edge deployment, building an enterprise AI model factory and intelligent computing infrastructure.
Model Training Pitfalls: Complex Environments, Resource Waste, Isolated Evaluation and Deployment
Enterprises want to train their own vertical models but face difficult GPU environment setup, disjointed large/small model training flows, lack of gates for evaluation and deployment, and lack of unified edge-cloud management. AIBase integrates large model fine-tuning, small model full training, evaluation gates, model release and edge-cloud synergy into one platform, with domestic chips and NVIDIA dual support, making the entire journey from training to production controllable.
Dual-Track Training, Separated Deployment
Large model fine-tuning and small model full training have independent entries, ensuring models of different sizes are delivered via optimal paths
Large Model Track
Model Asset Management
Unified management of large model version evolution, fine-tuning task lineage, online deployment instances and artifact inventory; three-step import wizard for zero-barrier onboarding of existing assets.
Fine-Tuning Task Center
Wizard-based fine-tuning task creation, selecting base version, fine-tuning dataset, training image and GPU specs; Loss/learning rate real-time visualization, logs and checkpoints online viewing.
Artifact Repository
Independently manage fine-tuning output adapters or incremental weights, stored by type and format, supporting binding to specific model versions for structured reuse of training成果.
Prefetch Matrix
Heatmap showing 'deployment × node' weight prefetch readiness, troubleshooting before go-live to ensure large model service startup is foolproof.
Release Gate
Evaluation gate mandatory association; versions failing evaluation cannot enter release flow, released versions support deactivation and rollback.
Small Model Track
Small Model Full Training
Supports classification, detection, segmentation, NER and other task types, independent task entry and capability configuration, not interfering with large model fine-tuning flow.
Edge Deployment
Supports deploying lightweight models to edge nodes, edge-cloud collaborative scheduling, adapting to factory/store and other compute-constrained edge inference scenarios.
Data Labeling Workbench
Built-in labeling workbench for processing dialogue corpora and instruction data, producing high-quality samples directly serving training, natively connected to DataHub training datasets.
Training Image Management
Package deep learning frameworks, dependency libraries and runtime scripts into standard training images, one-click selection, ensuring highly consistent and reproducible training environments.
Experiment Comparison
Select base version and candidate versions, run comparison experiments on the same evaluation set, produce multi-dimensional metric comparison reports, providing scientific decision basis for model iteration.
AI-Assisted Capabilities
Focused on intelligence of training, evaluation and online operations, clearly bounded from DataHub-assisted modeling
| Capability | Large Model Scenario | Small Model Scenario |
|---|---|---|
| Smart Training Assistant | Recommend optimal hyperparameters, compute specs and training images based on fine-tuning data profile and base model characteristics. | Recommend backbone, training parameters and compute specs based on task type and data distribution. |
| Training Anomaly Diagnosis | Automatically interpret training failure logs, analyze common causes such as OOM and gradient explosion, and give retry suggestions. | Automatically analyze training interruption causes such as data format errors and missing labels, quickly locating problems. |
| Experiment Report Summary | Automatically summarize base and fine-tuned version comparison experiments, generating factual, safety, fluency readable conclusions and tuning directions. | Automatically interpret multiple candidate small model metric comparisons, giving optimal selection suggestions and potential improvement directions. |
| Online Effect Diagnosis | Combined with call tracing and downvote feedback, identify increased hallucination and performance degradation of large models, prompting optimization or version rollback. | Analyze small model inference latency increase and accuracy decline, prompting whether retraining or deployment environment upgrade is needed. |
| Capacity Advisor | Based on historical GPU usage of large model training and inference, recommend scaling up or down to balance cost and efficiency. | Based on batch small model task queues and edge node utilization, provide compute scheduling optimization suggestions. |
Full Chain from GPU Cluster Training to Service
Distributed GPU training → model evaluation → containerized packaging → API service release, full observability and auditing

Compute Specification Support
Domestic Ascend (including latest 950 series), Cambricon MLU series and full NVIDIA GPU triple support, unified management of edge inference nodes
Platform Capability Assurance
Dual-Track Training, Separated Deployment
Large model fine-tuning and small model full training have independent task entries, capability configurations and deployment strategies, ensuring models of different sizes are delivered via optimal paths.
Data Integration, Clear Responsibilities
Natively connected to DataHub training datasets, providing cross-application data selection, preview, auditing and one-click training start. DataHub manages data, AIBase manages models, with clear boundaries.
Four Built-In Quality Gates
Dataset quality inspection, experiment comparison, evaluation gate, release checklist—four lines of defense ensure every production model meets standards.
Landing Scenarios
Typical enterprise scenarios for vertical model training and private deployment

Vertical Large Model Fine-Tuning
Finance, government, healthcare and other industries fine-tune domain large models based on their own data, all within private environments, with evaluation gates ensuring models meet production standards before release.
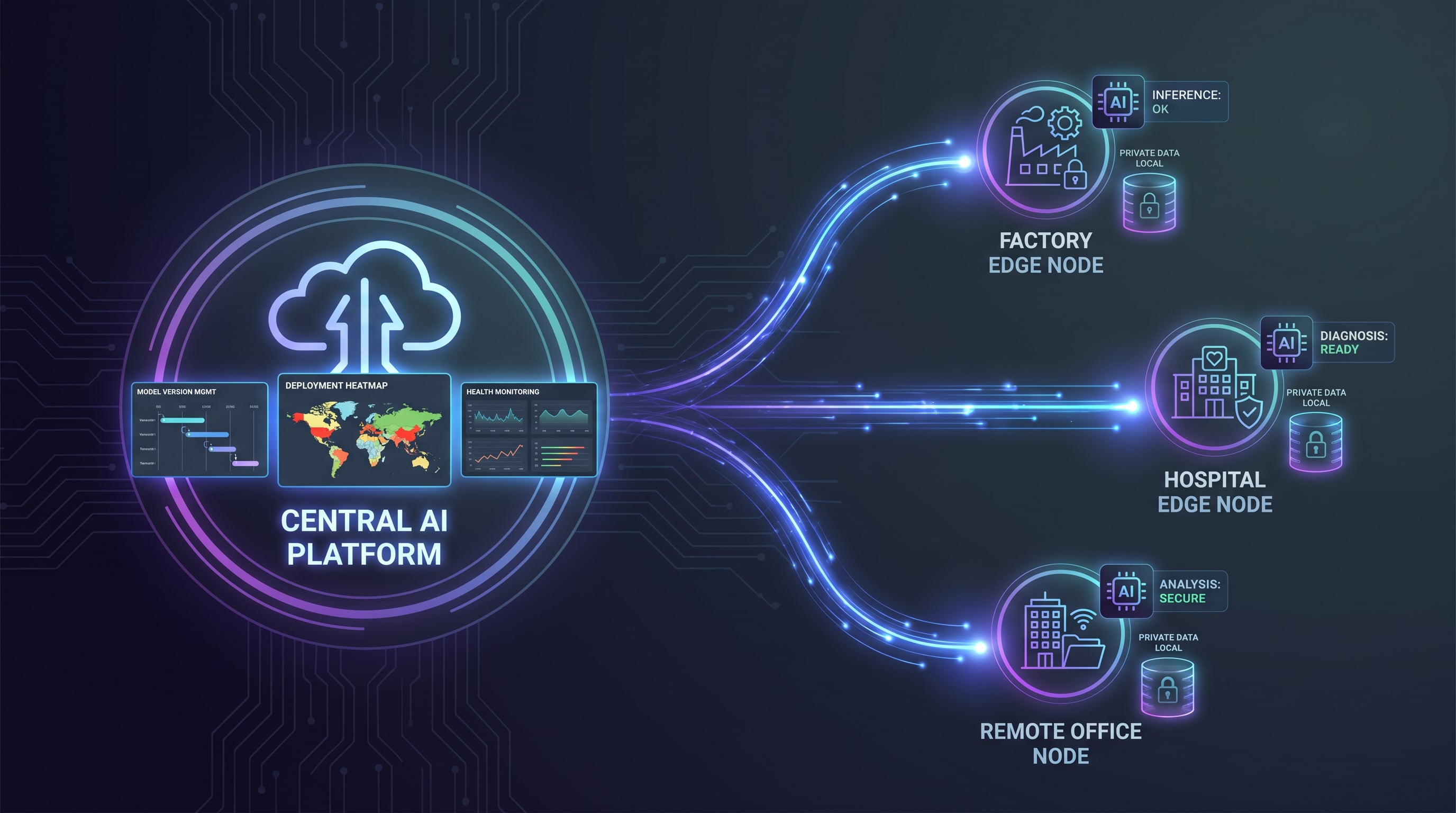
Edge-Cloud Collaborative Private Deployment
Manufacturing, energy, transportation and other industries with data security requirements achieve model private deployment under edge-cloud collaborative architecture, unified management of edge inference nodes, data does not leave the premises.
Build an Enterprise AI Model Factory
Natively connected to DataHub, seamless connection from data preparation to training start, model release protected by gates