AIBaseAI 智算基建
大模型微调与小模型全量训练双轨并行,从数据准备、训练、评测到发布与边缘部署,构建企业级 AI 模型工厂与智算基础设施。
模型训练陷阱:环境复杂、资源浪费、评测与部署孤立
企业希望训练自己的垂直模型,却面临:GPU 环境搭建困难、大小模型训练流程各自为政、评测与部署缺乏门禁、边云协同缺乏统一管理。AIBase 将大模型微调、小模型全量训练、评测门禁、模型发布与边云协同整合为一个平台,国产芯片与 NVIDIA 双路支撑,让模型从训练到上线全程可控。
双轨训练,分治部署
大模型微调与小模型全量训练拥有独立入口,确保不同体量的模型均按最优路径交付
大模型赛道
模型资产管理
统一管理大模型版本演进、微调任务血缘、线上部署实例与产物清单,三步导入向导零门槛纳管存量资产。
微调任务中心
向导式创建微调任务,选定基座版本、微调数据集、训练镜像与 GPU 规格,Loss/学习率实时可视,日志与检查点在线查看。
产物仓库
独立管理微调产出的适配器或增量权重,按类型与格式存储,支持与具体模型版本绑定,实现训练成果结构化复用。
预取矩阵
以热力图展示「部署×节点」的权重预取就绪情况,上线前排障,确保大模型服务启动万无一失。
发布门禁
评测门禁强制关联,未通过评测的版本无法进入发布流程,已发布版本支持停用与回滚。
小模型赛道
小模型全量训练
支持分类、检测、分割、NER 等任务类型,独立任务入口与能力配置,与大模型微调流程互不干扰。
边缘部署
支持将轻量模型部署至边缘节点,边云协同调度,适配工厂、门店等算力受限的边侧推理场景。
数据标注工作台
内置标注工作台,对对话语料、指令数据进行加工,产出直接服务于训练的高质量样本,与 DataHub 训练数据集原生衔接。
训练镜像管理
将深度学习框架、依赖库与运行脚本封装为标准训练镜像,一键选用,确保每次训练环境高度一致可复制。
实验对比
选择基座版本与候选版本,在相同评测集上运行对比实验,产出多维指标对比报告,为模型迭代提供科学决策依据。
AI 辅助能力
聚焦于训练、评测与线上运营的智能化,与 DataHub 辅助建模界限明确
| 能力 | 大模型场景 | 小模型场景 |
|---|---|---|
| 智能训练助手 | 根据微调数据画像与基座模型特性,推荐最佳超参、算力规格与训练镜像。 | 结合任务类型与数据分布,推荐 backbone、训练参数与算力规格。 |
| 训练异常诊断 | 自动解读训练失败日志,分析 OOM、梯度爆炸等常见原因,给出重试建议。 | 自动分析训练中断原因,如数据格式错误、标签缺失等,快速定位问题。 |
| 实验报告摘要 | 自动总结基座与微调版本对比实验,生成事实性、安全性、流畅度可读结论与调优方向。 | 自动解读多个候选小模型指标对比,给出最优选型建议与潜在提升方向。 |
| 线上效果诊断 | 结合调用追踪与点踩反馈,识别大模型幻觉增加、性能衰退,提示优化或版本回滚。 | 分析小模型推理延迟上升、准确率下降原因,提示是否需要重新训练或升级部署环境。 |
| 容量顾问 | 基于大模型训练与推理的历史 GPU 用量,建议扩容或缩容,平衡成本与效率。 | 根据批量小模型任务队列与边缘节点使用率,提供算力调度优化建议。 |
GPU 集群训练到服务全链路
分布式 GPU 训练 → 模型评估 → 容器化打包 → API 服务发布,全程可观测与审计

算力规格支持
国产昇腾(含最新 950 系列)、寒武纪 MLU 系列与 NVIDIA 全系 GPU 三路支持,边缘推理节点统一纳管
平台能力保障
双轨训练,分治部署
大模型微调与小模型全量训练拥有独立的任务入口、能力配置与部署策略,确保不同体量的模型均按最优路径交付。
数据一体,职责清晰
与 DataHub 训练数据集原生衔接,提供跨应用数据选择、预览、审计与一键开训。DataHub 管数据,AIBase 管模型,边界分明。
质量内建四道防线
数据集质检、实验对比、评测门禁、发布检查单四道防线,让每一个上线的模型都达到生产标准。
落地场景
垂直模型训练与私有化部署的典型企业场景

垂直大模型微调
金融、政务、医疗等行业基于自有数据微调行业大模型,全程在私有化环境内完成,评测门禁确保模型达到生产标准再上线。
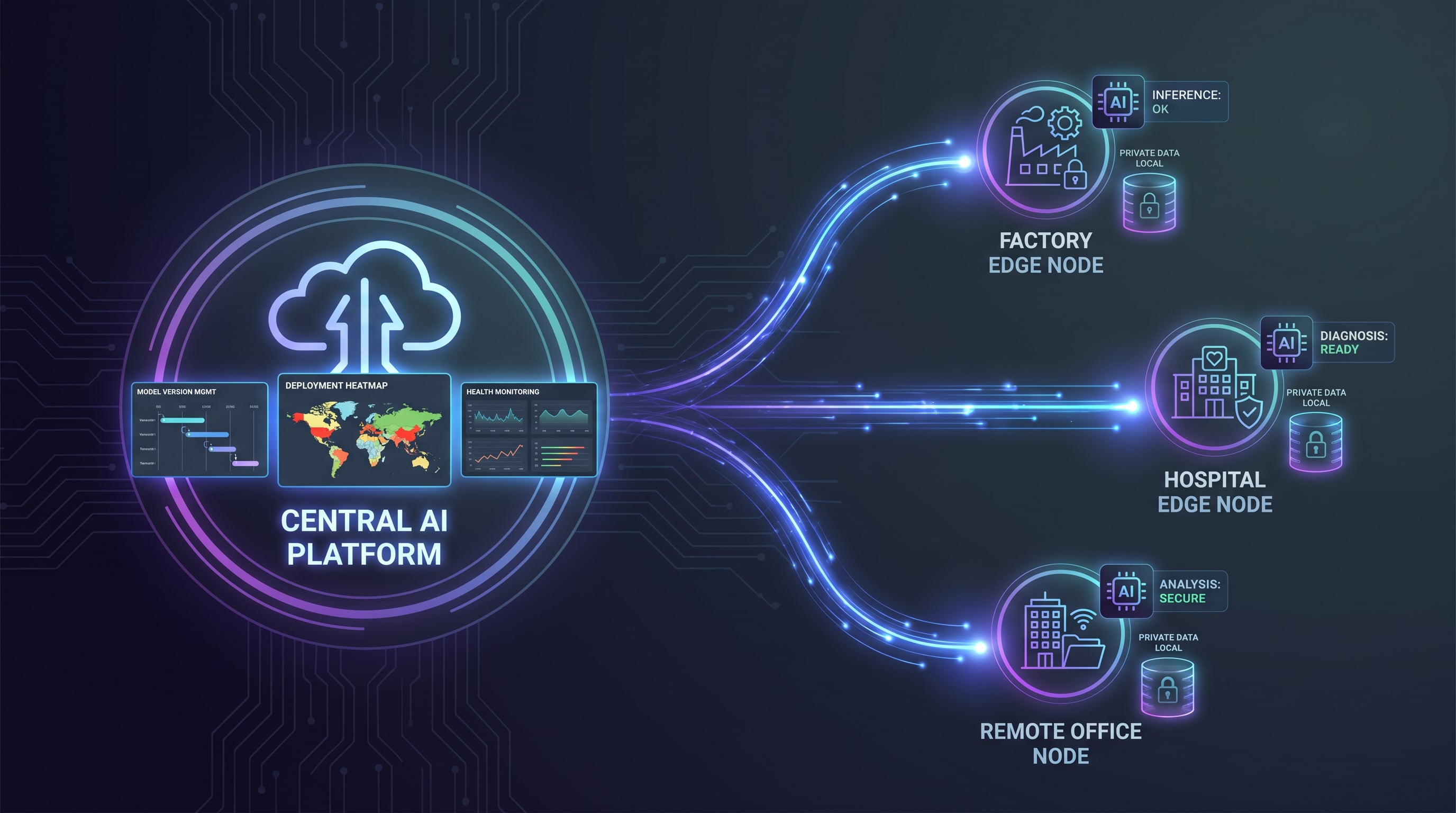
边云协同私有化部署
制造、能源、交通等对数据安全有要求的行业,在边云协同架构下实现模型私有化部署,边缘推理节点统一纳管,数据不出境。
构建企业级 AI 模型工厂
与 DataHub 原生衔接,数据准备到启动训练无缝衔接,模型上线有门禁保障