DataHubData Middle Platform
Not a traditional data warehouse, but a trustworthy data foundation built around and for AI. Evolve data from 'stored' to 'usable', ultimately to 'AI does the work'.
Scattered Data Assets, Governance and AI Applications Working in Silos
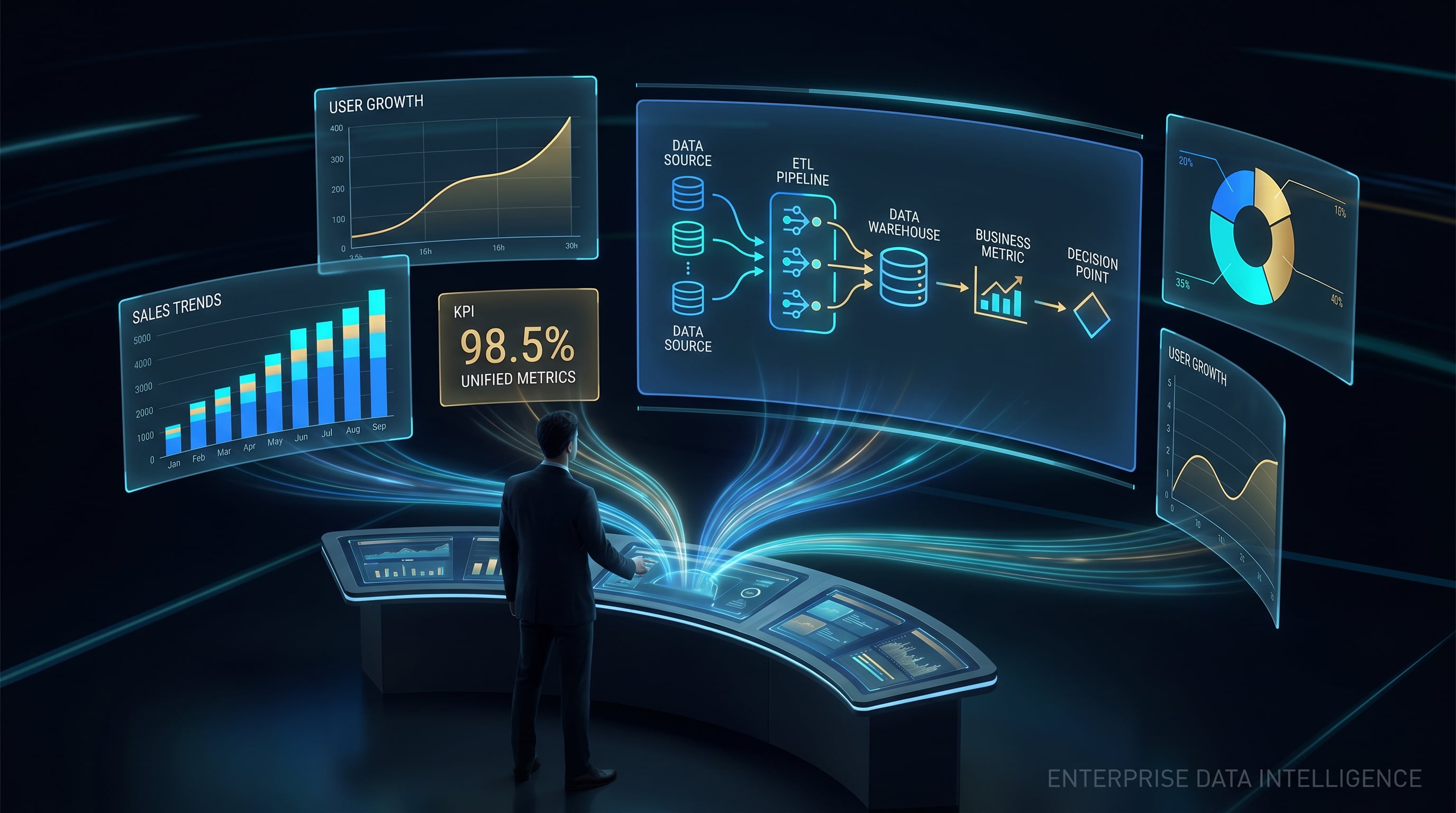
Most enterprises face data silos across systems, inconsistent metric definitions, hard-to-trace quality issues, and data assets that cannot directly provide training ammunition for AI models. DataHub integrates lakehouse storage, visual data processing, standardized governance, training dataset management, and data serviceization into a closed-loop platform, making data controllable from ingestion to service release and natively supporting AI applications.
Six Capability Domains
Covering the complete chain from data ingestion, storage, processing, governance to serviceization and AI integration, 47+ core features
End-to-End Data Governance Flow
From multi-source ingestion to AI consumption, every link is under governance control

AI-Assisted Capabilities
Focused on lowering governance barriers and improving operations efficiency, complementing AIBase's assisted training
Intelligent Modeling & Data Discovery
Automatically recommend logical models and metric drafts based on business descriptions, suggest quality rules and interpret failure root causes, allowing business users to participate in modeling and quality governance.
Knowledge Assistant
Automatically recommend chunking and Embedding strategies by document type, root-cause analysis when recall fails, accelerating knowledge go-live.
Operations Assistant
Interpret collection and pipeline running logs, give disposal suggestions, shortening failure recovery time.
Skill Discovery
Automatically identify data services that can be packaged as standardized Skills, promoting data capability assetization.
Platform Capability Assurance
End-to-End Closed Loop
From multi-source ingestion, lakehouse storage, visual processing, standard governance to service release and knowledgeization, all in one product.
Batch-Stream Unified
Supports batch collection, CDC near real-time, Flink stream processing, video stream ingestion, adapting to full-scenario data latency requirements.
Governance Built-In
Standards, quality, security, and master data run through the entire data chain, not after-the-fact patches.
AI-Ready
Native training dataset governance, knowledgeization and recall debugging, directly providing standardized data ammunition for model training and intelligent applications.
Open Ecosystem
Data service APIs, subscription push, event routing and open keys enable DataHub's data capabilities to be safely consumed by external systems and the Skill ecosystem.
Landing Scenarios
Typical enterprise applications of data governance and AI enablement

Group-Level Data Governance
Multi-business unit data converges into the lake, unified metric definitions and master data standards, quality rules automatically scan and one-click repair, data asset catalog globally visible.
AI Training Data Preparation
Built-in model training dataset flow, supporting cross-application data selection, preview, auditing and one-click training start. DataHub manages data, AIBase manages models, with clear boundaries.
Build a Continuously Evolving Data Asset System
Natively coupled with AIHub, DataHub governance results directly enter the knowledge base; data and agents are no longer two separate systems